Per leggere libri di narrativa in abbonamento oggigiorno si hanno a disposizione molti servizi online da Kindle Unlimited a Kobo Plus, ma non esiste nulla come Perlego, il primo servizio, attivo in tutto il mondo, specializzato sui libri universitari, sulla saggistica e sulla divulgazione scientifica (tra cui anche pubblicazioni e dispense). Il tutto sottoscrivendo semplicemente un abbonamento mensile da 12€ (che diventano 8€ se lo si paga annualmente) e cioè meno della metà del prezzo di un singolo libro.
Il modello di business che ha adottato Perlego è lo stesso di Netflix o Spotify (tanto da esser definita come la Spotify dei libri universitari) e permette, sottoscrivendo un unico abbonamento, di consultare (da pc, tablet o smartphone con apposita app) in modo illimitato riviste, articoli e testi accademici, professionali e di saggistica in ben 7 lingue diverse, con 24 diversi argomenti principali e più di 950 argomenti secondari, che spaziano dall’economia alla filosofia, dal management all’arte. Con oltre 1.000.000 di titoli professionali e accademici ricercabili e filtrabili, è in grado di soddisfare le esigenze di molti ricercatori o semplicemente curiosi.

L’idea
L’idea di Perlego è nata quando i due fondatori, Gauthier e Matt, erano studenti alle prese con il caro libri, che dovevano acquistare volumi di testo di centinaia di dollari, solo per usarli per un compito, o magari, per un piccolo passaggio! Da questa esigenza è nata, Perlego (che in latino significa “io leggo”), puntando sin dall’inizio sulla componente “democratica” della tecnologia, e sostenendo che l’istruzione sia un diritto umano (perchè ha il potere di trasformare la vita), l’hanno di fatto resa accessibile a tutti abbassando i costi di ingresso per un percorso accademico, evitando di dover comprare decine di libri specialistici per poter scrivere una tesi.
Gli studenti universitari, quindi, possono accedere in modo illimitato, da pc o da tablet e smartphone con apposita app, ad una intera biblioteca accademica. Il tutto si completa di funzionalità quali la possibilità di evidenziare porzioni di testo, prendere appunti o citare fonti. Non è invece possibile, per ovvi motivi di tutela del copyright, scaricare il file del titolo selezionato, che rimane fruibile solo in modalità streaming. Per alimentare questo sistema, Perlego ha stretto accordi con molti editori tra cui i principali editori dell’editoria universitaria mondiale, come Cambridge University Press, Routledge, Stanford University Press, Harvard University Press ed Elsevier.
Non solo per studenti
Perlego, però, oltre che per gli studenti, si rivolge anche ai professionisti che desiderano mantenere aggiornate le proprie conoscenze e hanno bisogno di accedere alle riviste e ai libri accademici che informano il loro settore, tutto in un unico posto a un basso costo.
Questo servizio può essere interessante anche tra i lettori abituali che, come il sottoscritto, amano leggere la saggistica. Infatti, sebbene i testi accademici e le riviste siano il focus della azienda, Perlego contiene anche importanti libri di saggistica scritti per un pubblico generalista. Infatti, per esempio, vi sono anche testi sullo sviluppo personale, arti dello spettacolo ma non mancano anche libri di narrativa e classici di autori di tutto il mondo. Ho potuto constatare che, per gli argomenti di mio interesse, ho trovato una ricca quantità di volumi anche grazie al recente accordo con Mondadori, Rizzoli, Einaudi, Piemme e Mondadori Electa che hanno ampliato ulteriormente il catalogo italiano, rendendo accessibili ulteriori 9.000 ebook tra saggistica, divulgazione scientifica e narrativa.
Come funziona
Perlego è una piattaforma davvero intuitiva disponibile sia nella versione desktop sia mobile, da cui è possibile leggere libri, aggiungere pagine ai segnalibri, evidenziare, prendere appunti e citare fonti, oltre a permettere la lettura dei testi anche offline. All’interno del sito web o dell’app, si avranno accesso a tutte le funzionalità di ricerca e annotazione di Perlego e si potranno effettuare ricerche nel catalogo di testi per cercare titoli, numeri ISBN o termini importanti.
E’ ovviamente anche possibile sfogliare per categoria: la libreria di Perlego è suddivisa in categorie disciplinari, ma puoi anche cercare tra sottocategorie, tag di genere, elenchi di letture, nomi di autori, date di pubblicazione e lingua (inglese, francese, tedesco, italiano, portoghese, spagnolo, svedese).
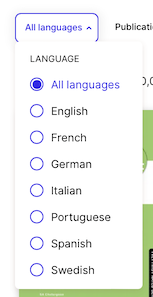
Il catalogo di libri in italiano, al momento in cui scrivo, è fornito di oltre 70.000 libri che, anche se non comparabile con la quantità di libri in lingua inglese che arriva a superare il milione di libri, non credo sia un limite per chi, come gli studenti, è abituato a padroneggiare la lingua di Albione.
Perlego non è solo una piattaforma di lettura, ma anche uno strumento di studio e di apprendimento. Infatti, grazie alle sue funzionalità avanzate, gli utenti possono sfruttare al meglio i contenuti offerti da Perlego. Ad esempio, è possibile evidenziare e annotare i testi, per creare delle flashcard e poter ripassare i concetti chiave, oltre generare delle citazioni automatiche per le proprie ricerche e condividere le proprie note con altri utenti.
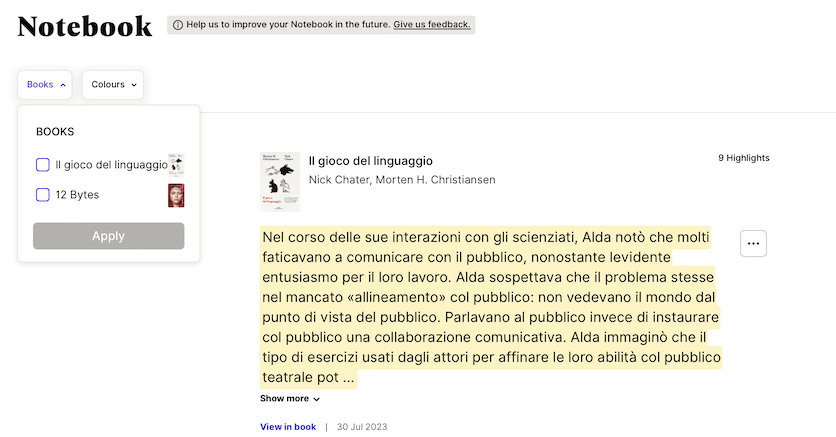
Ho trovato anche molto utile la possibilità di filtrare le proprie note, sia per libro sia per i diversi colori di evidenziazione usati:

Per i lettori appassionati di informatica, Perlego offre una vasta scelta di titoli di qualità, sia in italiano che in inglese, che coprono vari ambiti della disciplina, come la programmazione, il web design, la sicurezza informatica, l’intelligenza artificiale, il machine learning, il big data oltre all’accesso a riviste e pubblicazioni scientifiche di prestigio. Tra i libri disponibili su Perlego si possono trovare opere di autori noti e autorevoli nel campo dell’informatica. Solo nella categoria Computer Science in lingua italiana possiamo trovare oltre 1.000 titoli, tra cui libri non posso non citare “Uno, nessuno, ChatGPT” a cui hanno collaborato molti autori del podcast di Digitalia.
Perlego, infine, offre ai suoi lettori anche la funzione di Read Aloud, ovvero poter ascoltare i contenuti dei propri libri. Per il momento, ufficialmente, è disponibile solo dal sito web e solo per alcuni libri in inglese ma ho trovato anche libri in italiano in cui questa funzione era già attiva.

Come abbonarsi a Perlego
Se siete interessati a Perlego ma non volete prendere subito l’impegno, questo servizio offre una prova gratuita di 7 giorni per i nuovi clienti in modo da poter valutare se vale la pena proseguire con un abbonamento completo. Al termine del periodo di prova, l’abbonamento inizierà automaticamente ma se non volete continuare, ricordatevi di annullare la prova entro i primi 7 giorni.
Perlego offre due abbonamenti entrambi garantiscono l’accesso illimitato all’intera libreria: un abbonamento mensile da 12€ (cioè meno della metà del prezzo di un singolo libro) e uno annuale da 96€ l’anno (che sarebbero come se pagaste 8€ al mese). Entrambi i piani offrono una lettura illimitata e accesso all’intera libreria di Perlego senza restrizioni o pagamenti in-app aggiuntivi perchè più lettura non equivale a più soldi, solo più conoscenza acquisita.











 Alle volte può sembrare che, quando vengono proposte soluzioni a riga di comando, ci si voglia complicare le cose nonostante esistano decine di altri modi, molto più user friendly, semplici, efficaci e veloci. Vi starete chiedendo per quale motivo una persona vorrebbe scaricare un file da riga di comando piuttosto che usare una delle tanti utility grafiche e gratuite disponibili o, più semplicemente, usare il download manager del proprio browser, che qualunque esso sia, svolge già efficacemente il proprio lavoro?
Alle volte può sembrare che, quando vengono proposte soluzioni a riga di comando, ci si voglia complicare le cose nonostante esistano decine di altri modi, molto più user friendly, semplici, efficaci e veloci. Vi starete chiedendo per quale motivo una persona vorrebbe scaricare un file da riga di comando piuttosto che usare una delle tanti utility grafiche e gratuite disponibili o, più semplicemente, usare il download manager del proprio browser, che qualunque esso sia, svolge già efficacemente il proprio lavoro?

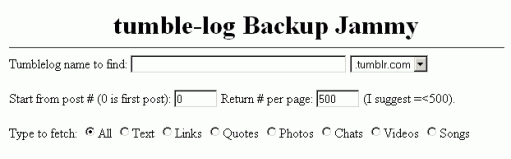
 Se, però, volete avere il completo controllo del vostro microblog, senza però dovervi affidare a servizi di terzi parti (che, diciamoci la verità, possono chiudere da un giorno all’altro senza l’obbligo di fornirvi un backup) ma non volete rinunciare alla semplicità di Tumblr, allora potete installare sul vostro sito,
Se, però, volete avere il completo controllo del vostro microblog, senza però dovervi affidare a servizi di terzi parti (che, diciamoci la verità, possono chiudere da un giorno all’altro senza l’obbligo di fornirvi un backup) ma non volete rinunciare alla semplicità di Tumblr, allora potete installare sul vostro sito, 



Commenti Recenti